Newsletter Subscribe
Enter your email address below and subscribe to our newsletter
Enter your email address below and subscribe to our newsletter
Free Tools


AI Fashion Models
Showcase outfits on AI models

Cleanup Pictures
Remove unwanted objects

Background Changer
AI generated instant backgrounds

Clothing Recolor
Replace color in 1 click

Image Recopyright
Get reimagine royalty-free photos

Background Remover
Transparent, or any color background

Photo Enhancer
Improve image quality
Download APP

You might already know how to come up with AI-generated images with the help of Stable Diffusion. Now, you can give those pictures a new life with AI-generated motion graphics as well. Welcome to Stable Video Diffusion which can help you turn your static images into dynamic videos. In this post, I will let you know every important thing about the Stable Diffusion Video Generation and how you can use it like a pro.

As you know, Stable Diffusion is an open-source AI model that is created by Stability AI. With Stable Diffusion, you can generate images by simply entering text prompts. Now, with the video version of Stable Diffusion, you can convert your images into short videos for free.
The AI model takes the image as a source frame and creates subsequent frames for it by using a unique technique, which is known as diffusion. The technique ideally adds various details (be it for the background or the object) to a source image, making it a video. Stability AI has trained the model based on a large set of realistic videos and photos, which can run virtually or on a local system.

Overall, Stable Video Diffusion is a powerful tool that can help you create all kinds of videos – from creative to educational content. While it has recently been released, the model is still in development, and is expected to evolve in the future.
Presently, you can use Stable Diffusion’s video feature in two ways – you can either install it on your system or leverage any web-based application.
Since Stable Diffusion AI video to video free solution is an open-source offering, various third-party tools have integrated it on their platforms. For instance, you can visit the website: https://stable-video-diffusion.com/ and upload your photo. Once the photo is uploaded, the tool will automatically analyze it and convert it into a video.
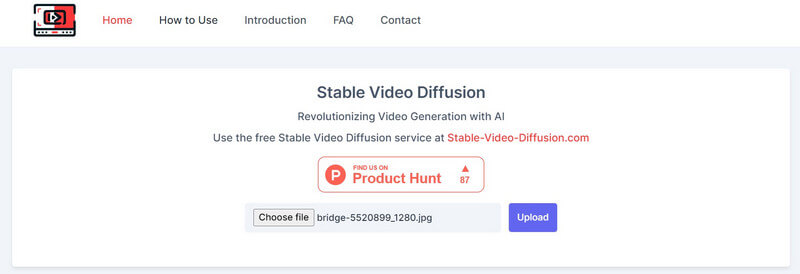
That’s it! In a few seconds, the online tool will generate a short video based on the uploaded photo. You can simply preview the video here and download it on your system.
If you want to get more customized (and unfiltered) results, then you can also consider installing the AI module from Stable Video Diffusion on your system. Though, you should know that the process is a bit technical and will consume substantial computing resources.
Prerequisites:
Once you have met the above requirements, you can launch Python’s console on your system. Now, you can run the following commands one by one, which will create, activate, and install the required dependencies on your system to run Stable Diffusion.
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
Once the environment is up and running on your system, you can prepare an input image. If you don’t have an image, you can use the standard Stable Diffusion AI to create one by entering text.
To generate the video, you can simply navigate the stable-video-diffusion direction on your system. Just enter the following command to generate the video, using an input image:
python3 scripts/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt “prompt text” –fps 6 –num_frames 100 –augmentation_level 0.5
Please note that in the above command, you need to do the following things:
After entering the prompt, you can wait for a while as the Stable Diffusion Video Generation completes its processing. If the process is more complex, then it might take a while for Stable Diffusion to generate its results.
Once the video generation is complete, it will be saved in the output directory with the timestamp as its name.
In this way, you can use the Stable Diffusion AI video to video free (or photo to video free) tool to generate videos. You can further experiment with various prompts and input settings to tweak the results.
In a nutshell, Stable Diffusion is an AI model created by Stability AI to generate high-quality media content (photos and videos). It is a more stable version of its previous models, which generates realistic images without errors.
On the other hand, Unstable Diffusion is its more creative and unrestricted counterpart. Unlike Stable Diffusion, which was trained on a dataset of filtered images, Unstable Diffusion has unfiltered images as its dataset. That’s why, Unstable Diffusion can often lead to errors in its results and produces more abstract work than realistic.

Since Stable Video Diffusion is still evolving, it is tough to predict its actual impact, but it can have the following influence:
As you know, Stable Diffusion can generate videos in seconds, which can help content creators save time. You can come up with animations, add special effects, or transfer styles of videos instantly instead of spending hours on editing.
Manual efforts that we put into video editing can be expensive and time-consuming. On the other hand, Stable Video Diffusion can help you reduce these editing costs by automating most of the post-production tasks.
Creators can now come up with videos beyond their restricted creativity with Stable Diffusion. For example, it can be used to generate videos with realistic special effects or to animate still images.
As I have discussed above, Stable Diffusion is an open-source tool, which is freely available to anyone. This makes it a valuable creative asset for anyone who wants to create videos, regardless of their skills or budget.

As the name suggests, the AI model is based on a diffusion practice that trains artificial intelligence to generate realistic media. It is based on three major principles:
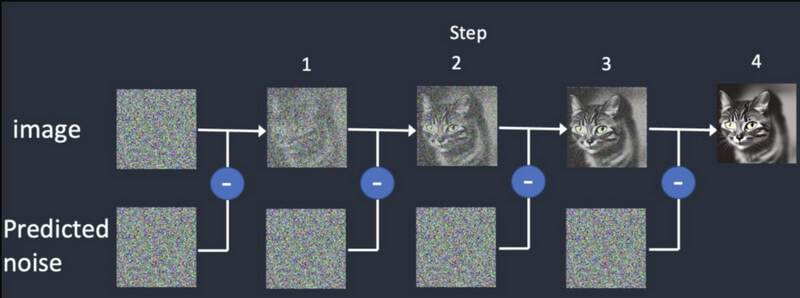
Diffusion: In diffusion, we first start with a random image and then keep adding more details to it gradually. It will keep providing different outputs until it matches the initial input. This will train the Stable Diffusion Video Generation to come up with synthetic frames, based on the initial one.
Training: Just like one image, the diffusion model is trained on a massive dataset. In this way, the AI model can easily distinguish and generate all kinds of realistic objects.
Video generation: Once the model is trained, users can load an image to the AI model. The model will refine the noise for each frame and come up with realistic outputs, based on the provided inputs for colors, rotations, visual shifts, etc.
Stable Video Diffusion is newly released and has several limitations, including the following:
The good news is that the current AI model of the Stable Video Diffusion is available for free. According to Stability AI, it has developed the model for research purposes as of now. You can access the model’s code on its GitHub page here: https://github.com/Stability-AI/generative-models
Besides that, you can access its documentation on Hugging Face here: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI has itself performed extensive research and compared its video generation model with other tools. According to the research, Stable Video Diffusion is compared with models like Runway and Pika Labs.

Here, you can see how these models perform for generating 14 and 25 frames at a customized rate of 3-30 fps. Stable Diffusion is also more powerful compared to Google Video Diffusion and DALL.E when it comes to generating realistic videos.
| Model | Strength | Weakness |
| Stable Video Diffusion | Realistic and coherent results, good for short videos from still images | Limited length, quality variations, limited creative control |
| Google Video Diffusion | Can generate longer videos, good for text-to-video generation | Can produce errors, requires fine-tuning (not that stable) |
| DALL-E 2 | Highly creative and experimental | Can be less stable |
| Runway ML | Easy to use and good for beginners | Limited capabilities and not as powerful as other models |
| Pika Labs | Open-source | Limited user base, still under development |
No – as of now, the results of the Stable Diffusion video generation are limited to up to 4 seconds only. However, in the upcoming versions of this AI, we might expect it to generate long-duration videos as well.
Here are some of the requirements for running Stable Video Diffusion:
| Requirement | Minimum | Recommended |
| GPU | 6GB VRAM | 10 GB VRAM (or higher) |
| CPU | 4 core | 8 core (or higher) |
| RAM | 16GB | 32GB(or higher) |
| Storage | 10GB | 20GB (or higher) |
Besides that, you should install Python 3.10 (or higher) on your system beforehand.
Presently, Stability AI has only released Stable Video Diffusion for research purposes so that the model can evolve. However, in the future, we might expect the AI model to evolve in the following features:
I’m sure that after reading this post, you can easily understand how the Stable Diffusion Video Generation works. I have also come up with some quick steps that you can take to get started with Stable Video Diffusion on your own. Though, you should remember that the AI model is relatively new, is still learning, and might not meet your exact requirements. Go ahead – give the Stability AI generative video model a try and keep experimenting with it to unleash your creative juices!