ニュースレターの購読
以下にメールアドレスを入力してニュースレターを購読してください
以下にメールアドレスを入力してニュースレターを購読してください

Stable Diffusionの助けを借りてAI生成画像を作成する方法をすでにご存知かもしれません。今なら、AI生成モーショングラフィックスでそれらの画像に新たな命を吹き込むこともできます。 安定した ビデオ 拡散 静止画像をダイナミックな動画に変換するのに役立ちます。この記事では、 安定した拡散ビデオ生成 プロのように使用する方法について説明します。

ご存知のとおり、Stable Diffusion は Stability AI が作成したオープンソースの AI モデルです。Stable Diffusion を使用すると、テキスト プロンプトを入力するだけで画像を生成できます。現在、Stable Diffusion のビデオ バージョンを使用すると、画像を無料で短いビデオに変換できます。
AI モデルは、画像をソース フレームとして受け取り、拡散と呼ばれる独自の技術を使用して、後続のフレームを作成します。この技術は、ソース イメージにさまざまな詳細 (背景やオブジェクトなど) を理想的に追加して、ビデオにします。Stability AI は、仮想的にもローカル システムでも実行できる、大量のリアルなビデオと写真に基づいてモデルをトレーニングしました。

全体、 安定した映像拡散 は、クリエイティブなコンテンツから教育的なコンテンツまで、あらゆる種類のビデオを作成するのに役立つ強力なツールです。最近リリースされましたが、このモデルはまだ開発中であり、今後進化することが期待されています。
現在、Stable Diffusion のビデオ機能は 2 つの方法で使用できます。システムにインストールするか、任意の Web ベースのアプリケーションを活用するかのいずれかです。
以来 安定した拡散AIビデオからビデオへの無料 このソリューションはオープンソースで提供されており、さまざまなサードパーティツールがそれをプラットフォームに統合しています。たとえば、次の Web サイトにアクセスしてください。 https://stable-video-diffusion.com/ 写真をアップロードします。写真をアップロードすると、ツールが自動的に写真を分析し、ビデオに変換します。
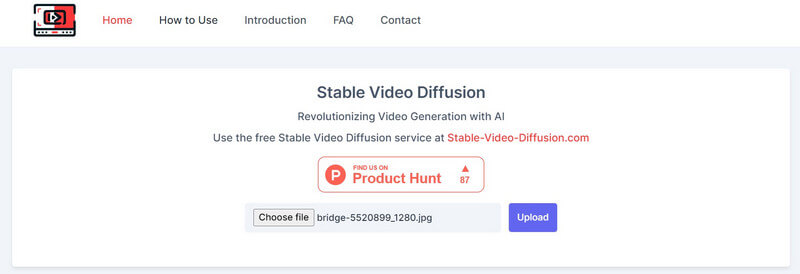
これで完了です。数秒で、オンライン ツールがアップロードされた写真に基づいて短いビデオを生成します。ここでビデオをプレビューし、システムにダウンロードすることができます。
よりカスタマイズされた(フィルタリングされていない)結果を取得したい場合は、AIモジュールのインストールも検討してください。 安定したビデオ 拡散 システム上で。ただし、このプロセスは少々技術的であり、かなりのコンピューティング リソースを消費することに注意してください。
前提条件:
上記の要件を満たしたら、システム上で Python のコンソールを起動できます。これで、次のコマンドを 1 つずつ実行できます。これにより、Stable Diffusion を実行するために必要な依存関係がシステムに作成、アクティブ化、インストールされます。
python3 -m venv venv
ソース venv/bin/activate
pip インストール -r 要件.txt
システム上で環境が起動したら、入力画像を準備できます。画像がない場合は、標準の Stable Diffusion AI を使用して、テキストを入力して画像を作成できます。
ビデオを生成するには、 安定したビデオ拡散 システムの指示に従ってください。入力画像を使用してビデオを生成するには、次のコマンドを入力するだけです。
python3 scripts/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt “プロンプトテキスト” –fps 6 –num_frames 100 –augmentation_level 0.5
上記のコマンドでは、次のことを行う必要があることに注意してください。
プロンプトを入力した後、しばらく待つと、 安定した拡散ビデオ生成 処理が完了します。プロセスがより複雑な場合は、Stable Diffusion が結果を生成するまでに時間がかかることがあります。
ビデオ生成が完了すると、 出力 タイムスタンプを名前として持つディレクトリ。
このようにして、 安定した拡散AIビデオからビデオへの無料 (または写真からビデオを無料で)ビデオを生成するツール。さまざまなプロンプトや入力設定を試して、結果を微調整することもできます。
一言で言えば、安定拡散とは AIモデル 高品質のメディア コンテンツ (写真や動画) を生成するために Stability AI によって作成されました。以前のモデルよりも安定したバージョンで、エラーのないリアルな画像を生成します。
一方、Unstable Diffusion は、よりクリエイティブで制限のない対応物です。フィルターされた画像のデータセットでトレーニングされた Stable Diffusion とは異なり、Unstable Diffusion のデータセットはフィルターされていない画像です。そのため、Unstable Diffusion では結果にエラーが発生することが多く、現実的なものよりも抽象的な作品が生成されます。

以来 安定した映像拡散 まだ進化しているため、実際の影響を予測するのは難しいですが、次のような影響を与える可能性があります。
ご存知のとおり、Stable Diffusion は数秒でビデオを生成できるため、コンテンツ作成者の時間を節約できます。編集に何時間も費やす代わりに、アニメーションを考案したり、特殊効果を追加したり、ビデオのスタイルを瞬時に転送したりできます。
ビデオ編集に手作業で取り組むと、費用と時間がかかります。一方で、 安定した映像拡散 ポストプロダクション作業のほとんどを自動化することで、編集コストを削減できます。
Stable Diffusion を使用すると、クリエイターは制限された創造性を超えたビデオを制作できるようになります。たとえば、リアルな特殊効果を使用したビデオを生成したり、静止画像をアニメーション化したりすることができます。
上で説明したように、Stable Diffusion はオープンソースのツールであり、誰でも無料で利用できます。そのため、スキルや予算に関係なく、ビデオを作成したい人にとっては貴重なクリエイティブ資産となります。

名前が示すように、AI モデルは、リアルなメディアを生成するために人工知能をトレーニングする拡散手法に基づいています。これは、次の 3 つの主要な原則に基づいています。
拡散拡散では、まずランダムな画像から始めて、徐々に詳細を追加していきます。最初の入力と一致するまで、さまざまな出力を提供し続けます。これにより、 安定した拡散ビデオ生成 最初のフレームに基づいて合成フレームを作成します。
トレーニング: 拡散モデルは、1枚の画像と同様に、膨大なデータセットでトレーニングされます。このようにして、AIモデルはあらゆる種類のリアルなオブジェクトを簡単に区別して生成できます。
ビデオ生成: モデルのトレーニングが完了すると、ユーザーは AI モデルに画像を読み込むことができます。モデルは、色、回転、視覚的なシフトなどの入力に基づいて、各フレームのノイズを改良し、リアルな出力を生成します。
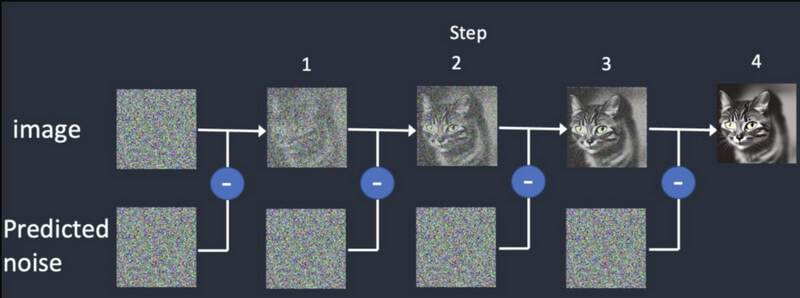
安定した映像拡散 は新しくリリースされており、次のようないくつかの制限があります。
良いニュースは、現在のAIモデルでは 安定した映像拡散 は無料でご利用いただけます。Stability AI によると、同社は現在、研究目的でこのモデルを開発しています。モデルのコードは、こちらの GitHub ページからアクセスできます。 https://github.com/Stability-AI/generative-models
それ以外にも、Hugging Face のドキュメントにはここからアクセスできます: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI は、自ら広範な研究を実施し、自社のビデオ生成モデルを他のツールと比較しました。研究によると、Stable Video Diffusion は Runway や Pika Labs などのモデルと比較されています。

ここでは、これらのモデルが 3 ~ 30 fps のカスタマイズされたレートで 14 フレームと 25 フレームを生成する場合のパフォーマンスを確認できます。リアルなビデオを生成するという点では、Stable Diffusion は Google Video Diffusion や DALL.E よりも強力です。
| モデル | 強さ | 弱点 |
| 安定した映像拡散 | リアルで一貫性のある結果、静止画像からの短い動画に最適 | 長さの制限、品質のバリエーション、クリエイティブなコントロールの制限 |
| Google ビデオの普及 | より長い動画を生成でき、テキストから動画を生成するのに適しています | エラーが発生する可能性があり、微調整が必要(それほど安定していない) |
| DALL-E 2 | 非常に創造的で実験的 | 安定性が低下する可能性がある |
| ランウェイML | 使いやすく初心者にも最適 | 機能が限られており、他のモデルほど強力ではない |
| ピカラボ | オープンソース | ユーザーベースが限られており、まだ開発中 |
いいえ、現時点では、 安定した拡散ビデオ生成 最大 4 秒までしか生成できません。ただし、この AI の今後のバージョンでは、長時間のビデオも生成できるようになると期待されます。
実行するための要件は次のとおりです 安定した映像拡散:
| 要件 | 最小 | 推奨 |
| グラフィックプロセッサ | 6GBのVRAM | 10 GB VRAM(またはそれ以上) |
| CPU | 4コア | 8コア(またはそれ以上) |
| ラム | 16ギガバイト | 32GB(またはそれ以上) |
| ストレージ | 10GB | 20GB(またはそれ以上) |
それに加えて、事前にシステムに Python 3.10 (またはそれ以降) をインストールする必要があります。
現在、安定性AIは 安定した映像拡散 モデルを進化させるための研究目的のため。ただし、将来的には、AI モデルが次の機能で進化することが期待されます。
この投稿を読めば、 安定した拡散ビデオ生成 動作します。また、始めるための簡単な手順もいくつかあります。 安定した映像拡散 自分自身で。しかし、覚えておいてほしいのは、 AIモデル 比較的新しいため、まだ学習中であり、お客様の要件に正確に適合しない可能性があります。さあ、Stability AI 生成ビデオ モデルを試して、実験を続け、創造力を解き放ちましょう。