Newsletter abonnieren
Geben Sie unten Ihre E-Mail-Adresse ein und abonnieren Sie unseren Newsletter
Geben Sie unten Ihre E-Mail-Adresse ein und abonnieren Sie unseren Newsletter
Kostenlose Tools


AI-Modelle
Vorzeige-Outfits auf AI-Modellen

Bilder aufräumen
Unerwünschte Objekte entfernen

Hintergrund-Wechsler
AI-generierte Sofort-Hintergründe

Kleidung Recolor
Ersetzen Sie die Farbe mit 1 Klick

Bild Recopyright
Holen Sie sich lizenzfreie Fotos von reimagine

Hintergrund-Entferner
Transparenter oder beliebig farbiger Hintergrund

Photo Enhancer
Verbesserung der Bildqualität
APP herunterladen

Sie wissen vielleicht bereits, wie Sie mithilfe von Stable Diffusion KI-generierte Bilder erstellen. Jetzt können Sie diesen Bildern auch mit KI-generierten Motion Graphics neues Leben einhauchen. Willkommen bei Stabil Video Diffusion mit dem Sie Ihre statischen Bilder in dynamische Videos verwandeln können. In diesem Beitrag werde ich Sie über alles Wichtige über die Stabile Diffusionsvideogenerierung und wie Sie es wie ein Profi verwenden können.

Wie Sie wissen, ist Stable Diffusion ein Open-Source-KI-Modell, das von Stability AI erstellt wurde. Mit Stable Diffusion können Sie Bilder generieren, indem Sie einfach Texteingaben vornehmen. Mit der Videoversion von Stable Diffusion können Sie Ihre Bilder jetzt kostenlos in kurze Videos umwandeln.
Das KI-Modell verwendet das Bild als Quellbild und erstellt mithilfe einer einzigartigen Technik, die als Diffusion bekannt ist, weitere Bilder dafür. Die Technik fügt einem Quellbild im Idealfall verschiedene Details (sei es für den Hintergrund oder das Objekt) hinzu und macht es so zu einem Video. Stability AI hat das Modell anhand einer großen Menge realistischer Videos und Fotos trainiert, die virtuell oder auf einem lokalen System ausgeführt werden können.

Gesamt, Stabile Videodiffusion ist ein leistungsstarkes Tool, mit dem Sie alle Arten von Videos erstellen können – von kreativen bis hin zu pädagogischen Inhalten. Obwohl es erst vor Kurzem veröffentlicht wurde, befindet sich das Modell noch in der Entwicklung und wird voraussichtlich in Zukunft weiterentwickelt.
Derzeit können Sie die Videofunktion von Stable Diffusion auf zwei Arten nutzen – Sie können sie entweder auf Ihrem System installieren oder eine beliebige webbasierte Anwendung nutzen.
Seit Stabile Diffusion AI Video zu Video kostenlos Lösung ist ein Open-Source-Angebot, verschiedene Drittanbieter-Tools haben es auf ihren Plattformen integriert. Sie können beispielsweise die Website besuchen: https://stable-video-diffusion.com/ und laden Sie Ihr Foto hoch. Sobald das Foto hochgeladen ist, analysiert das Tool es automatisch und wandelt es in ein Video um.
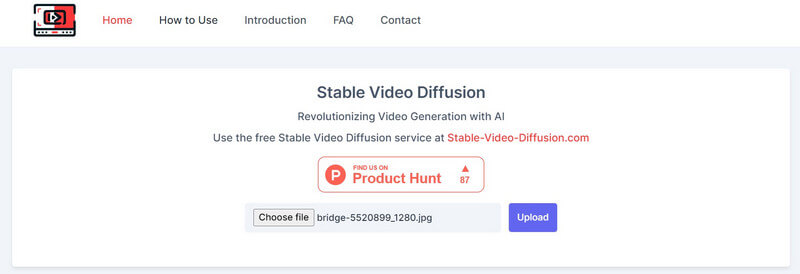
Das ist alles! Innerhalb weniger Sekunden generiert das Online-Tool ein kurzes Video basierend auf dem hochgeladenen Foto. Sie können das Video hier einfach in der Vorschau anzeigen und auf Ihr System herunterladen.
Wenn Sie individuellere (und ungefilterte) Ergebnisse erhalten möchten, können Sie auch das KI-Modul von installieren. Stabiles Video Diffusion auf Ihrem System. Sie sollten jedoch wissen, dass der Vorgang etwas technisch ist und erhebliche Computerressourcen verbraucht.
Voraussetzungen:
Sobald Sie die oben genannten Anforderungen erfüllt haben, können Sie die Python-Konsole auf Ihrem System starten. Jetzt können Sie die folgenden Befehle nacheinander ausführen, wodurch die erforderlichen Abhängigkeiten auf Ihrem System erstellt, aktiviert und installiert werden, um Stable Diffusion auszuführen.
python3 -m venv venv
Quelle venv/bin/activate
pip install -r Anforderungen.txt
Sobald die Umgebung auf Ihrem System eingerichtet und betriebsbereit ist, können Sie ein Eingabebild vorbereiten. Wenn Sie kein Bild haben, können Sie mit der standardmäßigen Stable Diffusion AI durch Eingabe von Text eines erstellen.
Um das Video zu generieren, navigieren Sie einfach durch die stabile Videodiffusion Richtung auf Ihrem System. Geben Sie einfach den folgenden Befehl ein, um das Video mit einem Eingabebild zu generieren:
python3 scripts/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt „Eingabeaufforderungstext“ –fps 6 –num_frames 100 –augmentation_level 0,5
Bitte beachten Sie, dass Sie im obigen Befehl die folgenden Dinge tun müssen:
Nach Eingabe der Eingabeaufforderung können Sie eine Weile warten, da die Stabile Diffusionsvideogenerierung seine Verarbeitung abschließt. Wenn der Prozess komplexer ist, kann es eine Weile dauern, bis Stable Diffusion seine Ergebnisse generiert.
Sobald die Videogenerierung abgeschlossen ist, wird es im Ausgabe Verzeichnis mit dem Zeitstempel als Namen.
Auf diese Weise können Sie die Stabile Diffusion AI Video zu Video kostenlos (oder kostenloses Foto-zu-Video-)Tool zum Generieren von Videos. Sie können außerdem mit verschiedenen Eingabeaufforderungen und Eingabeeinstellungen experimentieren, um die Ergebnisse zu optimieren.
Kurz gesagt ist die stabile Diffusion eine KI-Modell Erstellt von Stability AI zur Generierung hochwertiger Medieninhalte (Fotos und Videos). Es handelt sich um eine stabilere Version der Vorgängermodelle, die realistische Bilder ohne Fehler generiert.
Auf der anderen Seite ist Unstable Diffusion das kreativere und uneingeschränktere Gegenstück. Im Gegensatz zu Stable Diffusion, das mit einem Datensatz gefilterter Bilder trainiert wurde, hat Unstable Diffusion ungefilterte Bilder als Datensatz. Aus diesem Grund kann Unstable Diffusion häufig zu fehlerhaften Ergebnissen führen und erzeugt eher abstrakte als realistische Ergebnisse.

Seit Stabile Videodiffusion befindet sich noch in der Entwicklung und seine tatsächlichen Auswirkungen sind schwer vorherzusagen. Er kann jedoch folgenden Einfluss haben:
Wie Sie wissen, kann Stable Diffusion Videos in Sekundenschnelle erstellen, wodurch Inhaltsersteller Zeit sparen können. Sie können Animationen erstellen, Spezialeffekte hinzufügen oder Video-Stile sofort übertragen, anstatt Stunden mit der Bearbeitung zu verbringen.
Manueller Aufwand, den wir in die Videobearbeitung stecken, kann teuer und zeitaufwändig sein. Auf der anderen Seite Stabile Videodiffusion kann Ihnen helfen, diese Bearbeitungskosten zu senken, indem die meisten Nachbearbeitungsaufgaben automatisiert werden.
Mit Stable Diffusion können Videokünstler nun ihre eingeschränkte Kreativität ausleben. So können sie damit beispielsweise Videos mit realistischen Spezialeffekten erstellen oder Standbilder animieren.
Wie ich oben erläutert habe, ist Stable Diffusion ein Open-Source-Tool, das für jeden kostenlos verfügbar ist. Dies macht es zu einem wertvollen kreativen Hilfsmittel für jeden, der Videos erstellen möchte, unabhängig von seinen Fähigkeiten oder seinem Budget.

Wie der Name schon sagt, basiert das KI-Modell auf einer Diffusionspraxis, die künstliche Intelligenz darauf trainiert, realistische Medien zu generieren. Es basiert auf drei Hauptprinzipien:
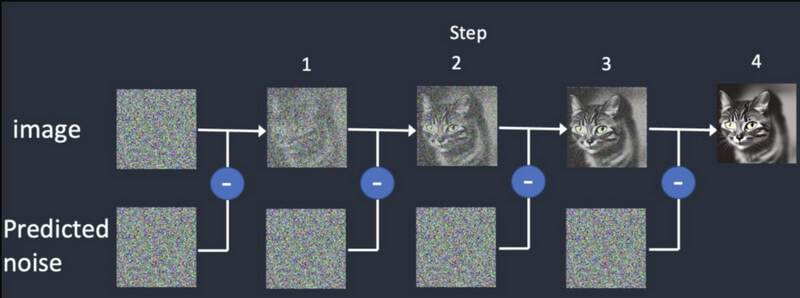
Diffusion: Bei der Diffusion beginnen wir zunächst mit einem zufälligen Bild und fügen ihm dann nach und nach weitere Details hinzu. Es werden so lange verschiedene Ausgaben geliefert, bis es mit der ursprünglichen Eingabe übereinstimmt. Dadurch wird das Stabile Diffusionsvideogenerierung synthetische Rahmen zu entwickeln, die auf dem ursprünglichen Rahmen basieren.
Ausbildung: Genau wie ein Bild wird das Diffusionsmodell anhand eines riesigen Datensatzes trainiert. Auf diese Weise kann das KI-Modell problemlos alle Arten realistischer Objekte unterscheiden und generieren.
Videogenerierung: Sobald das Modell trainiert ist, können Benutzer ein Bild in das KI-Modell laden. Das Modell verfeinert das Rauschen für jedes Bild und liefert realistische Ausgaben, basierend auf den bereitgestellten Eingaben für Farben, Rotationen, visuelle Verschiebungen usw.
Stabile Videodiffusion wurde neu veröffentlicht und weist mehrere Einschränkungen auf, darunter die folgenden:
Die gute Nachricht ist, dass das aktuelle KI-Modell der Stabile Videodiffusion ist kostenlos erhältlich. Laut Stability AI hat das Unternehmen das Modell derzeit zu Forschungszwecken entwickelt. Sie können den Code des Modells auf seiner GitHub-Seite hier abrufen: https://github.com/Stability-AI/generative-models
Darüber hinaus können Sie hier auf die Dokumentation zu Hugging Face zugreifen: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI hat selbst umfangreiche Untersuchungen durchgeführt und sein Videogenerierungsmodell mit anderen Tools verglichen. Laut der Untersuchung wird Stability Video Diffusion mit Modellen wie Runway und Pika Labs verglichen.

Hier können Sie sehen, wie diese Modelle bei der Generierung von 14 und 25 Bildern bei einer angepassten Rate von 3-30 fps abschneiden. Stable Diffusion ist im Vergleich zu Google Video Diffusion und DALL.E auch leistungsfähiger, wenn es um die Generierung realistischer Videos geht.
| Modell | Stärke | Schwäche |
| Stabile Videodiffusion | Realistische und stimmige Ergebnisse, gut für kurze Videos aus Standbildern | Begrenzte Länge, Qualitätsunterschiede, begrenzte kreative Kontrolle |
| Google Video Diffusion | Kann längere Videos generieren, gut für die Text-zu-Video-Generierung | Kann Fehler produzieren, erfordert Feinabstimmung (nicht so stabil) |
| DALL-E 2 | Hoch kreativ und experimentell | Kann weniger stabil sein |
| Laufsteg ML | Einfach zu bedienen und gut für Anfänger | Begrenzte Fähigkeiten und nicht so leistungsstark wie andere Modelle |
| Pika Labs | Open Source | Begrenzte Benutzerbasis, noch in der Entwicklung |
Nein – die Ergebnisse der Stabile Diffusion-Videoerzeugung sind auf maximal 4 Sekunden begrenzt. In den kommenden Versionen dieser KI können wir jedoch erwarten, dass sie auch Videos mit längerer Dauer generiert.
Hier sind einige der Voraussetzungen für den Betrieb Stabile Videodiffusion:
| Erfordernis | Minimum | Empfohlen |
| Grafikkarte | 6 GB VRAM | 10 GB VRAM (oder mehr) |
| CPU | 4 Kerne | 8 Kerne (oder höher) |
| RAM | 16 GIGABYTE | 32 GB (oder mehr) |
| Lagerung | 10 GB | 20 GB (oder mehr) |
Außerdem sollten Sie zuvor Python 3.10 (oder höher) auf Ihrem System installieren.
Derzeit hat Stability AI nur Stabile Videodiffusion zu Forschungszwecken, damit sich das Modell weiterentwickeln kann. In Zukunft können wir jedoch erwarten, dass sich das KI-Modell in den folgenden Merkmalen weiterentwickelt:
Ich bin sicher, dass Sie nach dem Lesen dieses Beitrags leicht verstehen können, wie die Stabile Diffusionsvideogenerierung funktioniert. Ich habe auch einige schnelle Schritte gefunden, die Sie unternehmen können, um loszulegen mit Stabile Videodiffusion auf eigene Faust. Sie sollten jedoch bedenken, dass die KI-Modell ist relativ neu, befindet sich noch in der Lernphase und erfüllt möglicherweise nicht genau Ihre Anforderungen. Probieren Sie das generative Videomodell von Stability AI aus und experimentieren Sie weiter damit, um Ihrer Kreativität freien Lauf zu lassen!