समाचार प्राप्त करें
अपना ईमेल पता नीचे दर्ज करें और हमारे न्यूज़लेटर की सदस्यता लें
अपना ईमेल पता नीचे दर्ज करें और हमारे न्यूज़लेटर की सदस्यता लें
निःशुल्क उपकरण


एआई फैशन मॉडल
एआई मॉडल पर आउटफिट प्रदर्शित करें

सफाई चित्र
अवांछित वस्तुओं को हटाएँ

पृष्ठभूमि परिवर्तक
AI द्वारा उत्पन्न त्वरित पृष्ठभूमि

कपड़ों का रंग बदलना
1 क्लिक में रंग बदलें

छवि पुनः कॉपीराइट
रॉयल्टी-मुक्त तस्वीरें प्राप्त करें

बैकग्राउंड रिमूवर
पारदर्शी, या किसी भी रंग की पृष्ठभूमि

फोटो एन्हांसर
छवि गुणवत्ता में सुधार करें
ऐप डाउनलोड करें

आप शायद पहले से ही जानते होंगे कि स्टेबल डिफ्यूजन की मदद से AI-जनरेटेड इमेज कैसे बनाई जाती है। अब, आप AI-जनरेटेड मोशन ग्राफ़िक्स की मदद से उन तस्वीरों को नया जीवन दे सकते हैं। आपका स्वागत है स्थिर वीडियो प्रसार जो आपकी स्थिर छवियों को गतिशील वीडियो में बदलने में आपकी मदद कर सकता है। इस पोस्ट में, मैं आपको इसके बारे में हर महत्वपूर्ण बात बताऊंगा स्थिर प्रसार वीडियो उत्पादन और आप इसे एक पेशेवर की तरह कैसे उपयोग कर सकते हैं।

जैसा कि आप जानते हैं, स्टेबल डिफ्यूजन एक ओपन-सोर्स AI मॉडल है जिसे स्टेबिलिटी AI द्वारा बनाया गया है। स्टेबल डिफ्यूजन के साथ, आप केवल टेक्स्ट प्रॉम्प्ट दर्ज करके इमेज जेनरेट कर सकते हैं। अब, स्टेबल डिफ्यूजन के वीडियो संस्करण के साथ, आप अपनी छवियों को मुफ्त में छोटे वीडियो में बदल सकते हैं।
AI मॉडल छवि को स्रोत फ़्रेम के रूप में लेता है और एक अनूठी तकनीक का उपयोग करके इसके लिए बाद के फ़्रेम बनाता है, जिसे प्रसार के रूप में जाना जाता है। यह तकनीक आदर्श रूप से स्रोत छवि में विभिन्न विवरण (चाहे वह पृष्ठभूमि के लिए हो या ऑब्जेक्ट के लिए) जोड़ती है, जिससे यह एक वीडियो बन जाता है। स्थिरता AI ने यथार्थवादी वीडियो और फ़ोटो के एक बड़े सेट के आधार पर मॉडल को प्रशिक्षित किया है, जो वर्चुअली या स्थानीय सिस्टम पर चल सकता है।

कुल मिलाकर, स्थिर वीडियो प्रसार एक शक्तिशाली उपकरण है जो आपको सभी प्रकार के वीडियो बनाने में मदद कर सकता है - रचनात्मक से लेकर शैक्षिक सामग्री तक। हालाँकि इसे हाल ही में रिलीज़ किया गया है, मॉडल अभी भी विकास में है, और भविष्य में इसके विकसित होने की उम्मीद है।
वर्तमान में, आप स्टेबल डिफ्यूजन की वीडियो सुविधा का उपयोग दो तरीकों से कर सकते हैं - या तो आप इसे अपने सिस्टम पर इंस्टॉल कर सकते हैं या किसी वेब-आधारित एप्लिकेशन का लाभ उठा सकते हैं।
तब से स्थिर प्रसार एआई वीडियो से वीडियो मुफ़्त समाधान एक ओपन-सोर्स पेशकश है, विभिन्न तृतीय-पक्ष उपकरणों ने इसे अपने प्लेटफ़ॉर्म पर एकीकृत किया है। उदाहरण के लिए, आप वेबसाइट पर जा सकते हैं: https://stable-video-diffusion.com/ और अपनी फोटो अपलोड करें। एक बार फोटो अपलोड हो जाने के बाद, टूल स्वचालित रूप से इसका विश्लेषण करेगा और इसे वीडियो में बदल देगा।
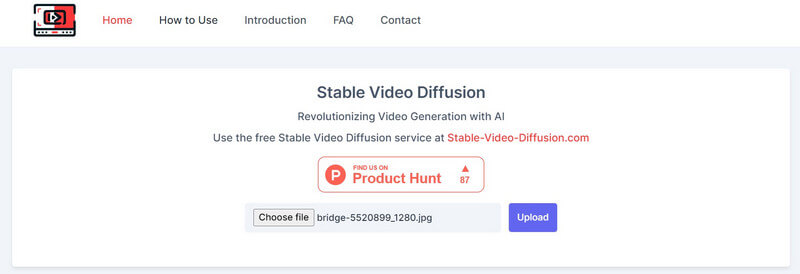
बस! कुछ ही सेकंड में, ऑनलाइन टूल अपलोड की गई फोटो के आधार पर एक छोटा वीडियो तैयार कर देगा। आप बस यहाँ वीडियो का पूर्वावलोकन कर सकते हैं और इसे अपने सिस्टम पर डाउनलोड कर सकते हैं।
यदि आप अधिक अनुकूलित (और अनफ़िल्टर्ड) परिणाम प्राप्त करना चाहते हैं, तो आप AI मॉड्यूल स्थापित करने पर भी विचार कर सकते हैं स्थिर वीडियो प्रसार आपके सिस्टम पर। हालाँकि, आपको पता होना चाहिए कि यह प्रक्रिया थोड़ी तकनीकी है और इसमें काफी कंप्यूटिंग संसाधन लगेंगे।
आवश्यक शर्तें:
एक बार जब आप उपरोक्त आवश्यकताओं को पूरा कर लेते हैं, तो आप अपने सिस्टम पर पायथन कंसोल लॉन्च कर सकते हैं। अब, आप एक-एक करके निम्नलिखित कमांड चला सकते हैं, जो स्टेबल डिफ्यूज़न को चलाने के लिए आपके सिस्टम पर आवश्यक निर्भरताएँ बनाएगा, सक्रिय करेगा और स्थापित करेगा।
python3 -m वेनव वेनव
स्रोत वेनव/बिन/सक्रिय
पाइप इंस्टॉल -आर आवश्यकताएँ.txt
एक बार जब पर्यावरण आपके सिस्टम पर चालू हो जाता है, तो आप एक इनपुट छवि तैयार कर सकते हैं। यदि आपके पास कोई छवि नहीं है, तो आप टेक्स्ट दर्ज करके एक छवि बनाने के लिए मानक स्थिर प्रसार AI का उपयोग कर सकते हैं।
वीडियो बनाने के लिए, आप बस नेविगेट कर सकते हैं स्थिर-वीडियो-प्रसार अपने सिस्टम पर दिशा निर्देश दर्ज करें। इनपुट छवि का उपयोग करके वीडियो बनाने के लिए बस निम्न कमांड दर्ज करें:
python3 स्क्रिप्ट/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –प्रॉम्प्ट “प्रॉम्प्ट टेक्स्ट” –fps 6 –num_frames 100 –augmentation_level 0.5
कृपया ध्यान दें कि उपरोक्त आदेश में, आपको निम्नलिखित कार्य करने होंगे:
प्रॉम्प्ट दर्ज करने के बाद, आप थोड़ी देर तक प्रतीक्षा कर सकते हैं क्योंकि स्थिर प्रसार वीडियो उत्पादन इसकी प्रोसेसिंग पूरी हो जाती है। अगर प्रक्रिया ज़्यादा जटिल है, तो स्टेबल डिफ़्यूज़न को अपने नतीजे देने में कुछ समय लग सकता है।
एक बार वीडियो निर्माण पूरा हो जाने पर, इसे सहेज लिया जाएगा आउटपुट टाइमस्टैम्प के साथ निर्देशिका को उसके नाम के रूप में रखें।
इस तरह, आप इसका उपयोग कर सकते हैं स्थिर प्रसार एआई वीडियो से वीडियो मुफ़्त (या फोटो से वीडियो फ्री) टूल वीडियो बनाने के लिए। आप परिणामों को बेहतर बनाने के लिए विभिन्न संकेतों और इनपुट सेटिंग्स के साथ आगे प्रयोग कर सकते हैं।
संक्षेप में, स्थिर प्रसार एक एआई मॉडल स्टेबिलिटी एआई द्वारा उच्च गुणवत्ता वाली मीडिया सामग्री (फोटो और वीडियो) बनाने के लिए बनाया गया। यह अपने पिछले मॉडलों का अधिक स्थिर संस्करण है, जो बिना किसी त्रुटि के यथार्थवादी चित्र बनाता है।
दूसरी ओर, अस्थिर प्रसार इसका अधिक रचनात्मक और अप्रतिबंधित प्रतिरूप है। स्थिर प्रसार के विपरीत, जिसे फ़िल्टर की गई छवियों के डेटासेट पर प्रशिक्षित किया गया था, अस्थिर प्रसार में फ़िल्टर न की गई छवियां इसके डेटासेट के रूप में हैं। यही कारण है कि अस्थिर प्रसार अक्सर अपने परिणामों में त्रुटियों को जन्म दे सकता है और यथार्थवादी की तुलना में अधिक अमूर्त कार्य उत्पन्न करता है।

तब से स्थिर वीडियो प्रसार अभी भी विकास हो रहा है, इसलिए इसके वास्तविक प्रभाव का अनुमान लगाना कठिन है, लेकिन इसका निम्नलिखित प्रभाव हो सकता है:
जैसा कि आप जानते हैं, स्टेबल डिफ्यूज़न कुछ ही सेकंड में वीडियो बना सकता है, जिससे कंटेंट क्रिएटर्स को समय बचाने में मदद मिल सकती है। आप एडिटिंग पर घंटों खर्च करने के बजाय तुरंत एनिमेशन बना सकते हैं, स्पेशल इफ़ेक्ट जोड़ सकते हैं या वीडियो की स्टाइल ट्रांसफर कर सकते हैं।
वीडियो संपादन में हम जो मैन्युअल प्रयास करते हैं, वह महंगा और समय लेने वाला हो सकता है। दूसरी ओर, स्थिर वीडियो प्रसार अधिकांश पोस्ट-प्रोडक्शन कार्यों को स्वचालित करके आप इन संपादन लागतों को कम करने में मदद कर सकते हैं।
स्टेबल डिफ्यूजन के साथ अब क्रिएटर्स अपनी सीमित रचनात्मकता से परे वीडियो बना सकते हैं। उदाहरण के लिए, इसका उपयोग यथार्थवादी विशेष प्रभावों वाले वीडियो बनाने या स्थिर छवियों को एनिमेट करने के लिए किया जा सकता है।
जैसा कि मैंने ऊपर बताया है, स्टेबल डिफ्यूज़न एक ओपन-सोर्स टूल है, जो किसी के लिए भी मुफ़्त में उपलब्ध है। यह इसे उन सभी लोगों के लिए एक मूल्यवान रचनात्मक संपत्ति बनाता है जो वीडियो बनाना चाहते हैं, चाहे उनके कौशल या बजट कुछ भी हों।

जैसा कि नाम से पता चलता है, एआई मॉडल एक प्रसार अभ्यास पर आधारित है जो यथार्थवादी मीडिया उत्पन्न करने के लिए कृत्रिम बुद्धिमत्ता को प्रशिक्षित करता है। यह तीन प्रमुख सिद्धांतों पर आधारित है:
प्रसार: प्रसार में, हम सबसे पहले एक यादृच्छिक छवि से शुरू करते हैं और फिर धीरे-धीरे उसमें और विवरण जोड़ते रहते हैं। यह तब तक अलग-अलग आउटपुट प्रदान करता रहेगा जब तक कि यह प्रारंभिक इनपुट से मेल नहीं खाता। यह प्रशिक्षित करेगा स्थिर प्रसार वीडियो उत्पादन प्रारंभिक फ्रेम के आधार पर सिंथेटिक फ्रेम तैयार करना।
प्रशिक्षण: एक छवि की तरह ही, प्रसार मॉडल को एक विशाल डेटासेट पर प्रशिक्षित किया जाता है। इस तरह, AI मॉडल आसानी से सभी प्रकार की यथार्थवादी वस्तुओं को पहचान सकता है और उत्पन्न कर सकता है।
वीडियो निर्माण: एक बार मॉडल प्रशिक्षित हो जाने के बाद, उपयोगकर्ता AI मॉडल में एक छवि लोड कर सकते हैं। मॉडल प्रत्येक फ्रेम के लिए शोर को परिष्कृत करेगा और रंगों, घुमावों, दृश्य बदलावों आदि के लिए दिए गए इनपुट के आधार पर यथार्थवादी आउटपुट देगा।
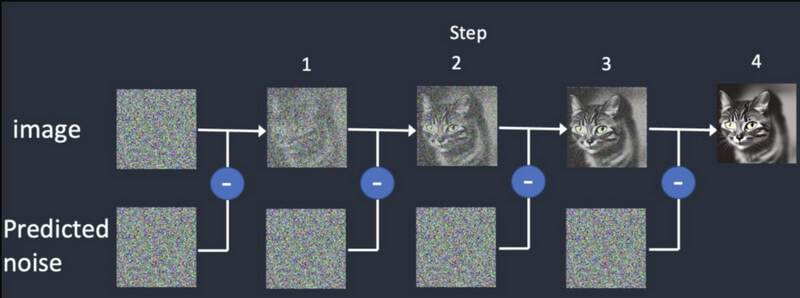
स्थिर वीडियो प्रसार यह नया संस्करण है और इसमें कई सीमाएँ हैं, जिनमें निम्नलिखित शामिल हैं:
अच्छी खबर यह है कि वर्तमान एआई मॉडल स्थिर वीडियो प्रसार यह मुफ़्त में उपलब्ध है। स्टेबिलिटी एआई के अनुसार, इसने अभी तक शोध उद्देश्यों के लिए मॉडल विकसित किया है। आप मॉडल के कोड को इसके GitHub पेज पर यहाँ देख सकते हैं: https://github.com/Stability-AI/generative-models
इसके अलावा, आप हगिंग फेस पर इसके दस्तावेज़ यहां देख सकते हैं: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
स्टेबिलिटी एआई ने खुद व्यापक शोध किया है और अपने वीडियो जेनरेशन मॉडल की तुलना दूसरे टूल्स से की है। शोध के अनुसार, स्टेबल वीडियो डिफ्यूजन की तुलना रनवे और पिका लैब्स जैसे मॉडलों से की गई है।

यहाँ, आप देख सकते हैं कि ये मॉडल 3-30 fps की कस्टमाइज्ड दर पर 14 और 25 फ्रेम बनाने के लिए कैसे प्रदर्शन करते हैं। यथार्थवादी वीडियो बनाने की बात करें तो स्टेबल डिफ्यूजन Google वीडियो डिफ्यूजन और DALL.E की तुलना में अधिक शक्तिशाली है।
| नमूना | ताकत | कमजोरी |
| स्थिर वीडियो प्रसार | यथार्थवादी और सुसंगत परिणाम, स्थिर छवियों से लघु वीडियो के लिए अच्छे | सीमित लंबाई, गुणवत्ता भिन्नता, सीमित रचनात्मक नियंत्रण |
| गूगल वीडियो प्रसार | लंबे वीडियो बना सकते हैं, टेक्स्ट-टू-वीडियो बनाने के लिए अच्छे हैं | त्रुटियाँ उत्पन्न हो सकती हैं, बारीक समायोजन की आवश्यकता होती है (स्थिर नहीं) |
| डैल-ई 2 | अत्यधिक रचनात्मक और प्रयोगात्मक | कम स्थिर हो सकता है |
| रनवे एमएल | उपयोग में आसान और शुरुआती लोगों के लिए अच्छा | सीमित क्षमताएं और अन्य मॉडलों की तरह शक्तिशाली नहीं |
| पिका लैब्स | खुला स्त्रोत | सीमित उपयोगकर्ता आधार, अभी भी विकासाधीन |
नहीं – अभी तक, परिणाम स्थिर प्रसार वीडियो उत्पादन केवल 4 सेकंड तक ही सीमित हैं। हालाँकि, इस AI के आने वाले संस्करणों में, हम उम्मीद कर सकते हैं कि यह लंबी अवधि के वीडियो भी बनाएगा।
यहां चलाने के लिए कुछ आवश्यकताएं दी गई हैं स्थिर वीडियो प्रसार:
| मांग | न्यूनतम | अनुशंसित |
| जीपीयू | 6जीबी वीआरएएम | 10 जीबी वीआरएएम (या अधिक) |
| CPU | 4 कोर | 8 कोर (या अधिक) |
| टक्कर मारना | 16जीबी | 32GB(या अधिक) |
| भंडारण | 10जीबी | 20GB (या अधिक) |
इसके अलावा, आपको पहले से ही अपने सिस्टम पर पायथन 3.10 (या उच्चतर) स्थापित करना चाहिए।
वर्तमान में, स्थिरता एआई केवल जारी किया गया है स्थिर वीडियो प्रसार शोध उद्देश्यों के लिए ताकि मॉडल विकसित हो सके। हालाँकि, भविष्य में, हम उम्मीद कर सकते हैं कि AI मॉडल निम्नलिखित विशेषताओं में विकसित होगा:
मुझे यकीन है कि इस पोस्ट को पढ़ने के बाद, आप आसानी से समझ सकते हैं कि कैसे स्थिर प्रसार वीडियो उत्पादन काम करता है। मैंने कुछ त्वरित कदम भी सुझाए हैं जिन्हें आप शुरू करने के लिए अपना सकते हैं स्थिर वीडियो प्रसार अपने दम पर। हालाँकि, आपको यह याद रखना चाहिए कि एआई मॉडल अपेक्षाकृत नया है, अभी भी सीख रहा है, और शायद आपकी सटीक आवश्यकताओं को पूरा न करे। आगे बढ़ें - स्टेबिलिटी AI जनरेटिव वीडियो मॉडल को आज़माएँ और अपनी रचनात्मकता को निखारने के लिए इसके साथ प्रयोग करते रहें!