Berlangganan Buletin
Masukkan alamat email Anda di bawah ini dan berlangganan buletin kami
Masukkan alamat email Anda di bawah ini dan berlangganan buletin kami
Alat Gratis


Model Busana AI
Menampilkan pakaian pada model AI

Gambar Pembersihan
Hapus objek yang tidak diinginkan

Pengubah Latar Belakang
Latar belakang instan yang dihasilkan AI

Pewarnaan Ulang Pakaian
Mengganti warna dalam 1 klik

Hak Cipta Gambar
Dapatkan foto bebas royalti yang ditata ulang

Penghilang Latar Belakang
Transparan, atau latar belakang warna apa pun

Penambah Foto
Meningkatkan kualitas gambar
Unduh aplikasi

Anda mungkin sudah mengetahui cara menghasilkan gambar yang dihasilkan AI dengan bantuan Difusi Stabil. Sekarang, Anda juga dapat memberikan kehidupan baru pada gambar-gambar itu dengan grafik gerak yang dihasilkan AI. Selamat Datang di Stabil Video Difusi yang dapat membantu Anda mengubah gambar statis menjadi video dinamis. Dalam posting ini, saya akan memberi tahu Anda semua hal penting tentang Pembuatan Video Difusi Stabil dan bagaimana Anda dapat menggunakannya seperti seorang profesional.

Seperti yang Anda ketahui, Difusi Stabil adalah model AI sumber terbuka yang dibuat oleh Stability AI. Dengan Difusi Stabil, Anda dapat menghasilkan gambar hanya dengan memasukkan perintah teks. Sekarang, dengan Stable Diffusion versi video, Anda dapat mengonversi gambar Anda menjadi video pendek secara gratis.
Model AI mengambil gambar sebagai bingkai sumber dan membuat bingkai berikutnya menggunakan teknik unik, yang dikenal sebagai difusi. Teknik ini idealnya menambahkan berbagai detail (baik itu latar belakang atau objek) ke gambar sumber, menjadikannya sebuah video. Stability AI telah melatih model berdasarkan sekumpulan besar video dan foto realistis, yang dapat dijalankan secara virtual atau pada sistem lokal.

Keseluruhan, Difusi Video Stabil adalah alat canggih yang dapat membantu Anda membuat semua jenis video – mulai dari konten kreatif hingga pendidikan. Meskipun baru dirilis, model ini masih dalam pengembangan, dan diperkirakan akan terus berkembang di masa mendatang.
Saat ini, Anda dapat menggunakan fitur video Stable Diffusion dengan dua cara – Anda dapat menginstalnya di sistem Anda atau memanfaatkan aplikasi berbasis web apa pun.
Sejak Video AI Difusi Stabil ke video gratis solusinya adalah penawaran sumber terbuka, berbagai alat pihak ketiga telah mengintegrasikannya pada platform mereka. Misalnya, Anda dapat mengunjungi situs web: https://stable-video-diffusion.com/ dan unggah foto Anda. Setelah foto diunggah, alat ini akan menganalisisnya secara otomatis dan mengubahnya menjadi video.
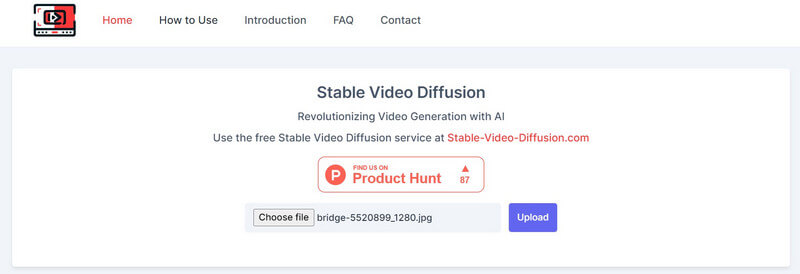
Itu dia! Dalam beberapa detik, alat online tersebut akan menghasilkan video pendek berdasarkan foto yang diunggah. Anda cukup melihat pratinjau video di sini dan mengunduhnya ke sistem Anda.
Jika Anda ingin mendapatkan hasil yang lebih disesuaikan (dan tanpa filter), Anda juga dapat mempertimbangkan untuk menginstal modul AI dari Video Stabil Difusi pada sistem Anda. Meskipun demikian, Anda harus tahu bahwa prosesnya agak teknis dan akan menghabiskan sumber daya komputasi yang besar.
Prasyarat:
Setelah Anda memenuhi persyaratan di atas, Anda dapat meluncurkan konsol Python di sistem Anda. Sekarang, Anda dapat menjalankan perintah berikut satu per satu, yang akan membuat, mengaktifkan, dan menginstal dependensi yang diperlukan pada sistem Anda untuk menjalankan Difusi Stabil.
python3 -m venv venv
sumber venv/bin/aktifkan
instalasi pip -r persyaratan.txt
Setelah lingkungan aktif dan berjalan di sistem Anda, Anda dapat menyiapkan gambar masukan. Jika Anda tidak memiliki gambar, Anda dapat menggunakan Stable Diffusion AI standar untuk membuatnya dengan memasukkan teks.
Untuk menghasilkan video, Anda cukup menavigasi difusi video stabil arah pada sistem Anda. Cukup masukkan perintah berikut untuk menghasilkan video, menggunakan gambar masukan:
skrip python3/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt “teks prompt” –fps 6 –num_frames 100 –augmentation_level 0.5
Harap dicatat bahwa dalam perintah di atas, Anda perlu melakukan hal-hal berikut:
Setelah memasukkan prompt, Anda dapat menunggu beberapa saat Pembuatan Video Difusi Stabil menyelesaikan pemrosesannya. Jika prosesnya lebih kompleks, mungkin diperlukan waktu beberapa saat agar Difusi Stabil dapat menghasilkan hasilnya.
Setelah pembuatan video selesai, video tersebut akan disimpan di keluaran direktori dengan stempel waktu sebagai namanya.
Dengan cara ini, Anda dapat menggunakan Video AI Difusi Stabil ke video gratis (atau foto ke video gratis) alat untuk menghasilkan video. Anda dapat bereksperimen lebih lanjut dengan berbagai petunjuk dan pengaturan masukan untuk mengubah hasilnya.
Singkatnya, Difusi Stabil adalah model AI dibuat oleh Stability AI untuk menghasilkan konten media berkualitas tinggi (foto dan video). Ini adalah versi yang lebih stabil dari model sebelumnya, yang menghasilkan gambar realistis tanpa kesalahan.
Di sisi lain, Difusi Tidak Stabil adalah versi yang lebih kreatif dan tidak terbatas. Berbeda dengan Difusi Stabil, yang dilatih pada kumpulan data gambar yang difilter, Difusi Tidak Stabil memiliki gambar tanpa filter sebagai kumpulan datanya. Oleh karena itu, Difusi Tidak Stabil seringkali dapat menyebabkan kesalahan pada hasil dan menghasilkan lebih banyak karya abstrak daripada realistis.

Sejak Difusi Video Stabil masih terus berkembang, sulit untuk memprediksi dampak sebenarnya, namun hal ini dapat mempunyai pengaruh sebagai berikut:
Seperti yang Anda ketahui, Difusi Stabil dapat menghasilkan video dalam hitungan detik, sehingga dapat membantu pembuat konten menghemat waktu. Anda dapat membuat animasi, menambahkan efek khusus, atau mentransfer gaya video secara instan daripada menghabiskan waktu berjam-jam untuk mengedit.
Upaya manual yang kami lakukan dalam pengeditan video bisa jadi mahal dan memakan waktu. Di samping itu, Difusi Video Stabil dapat membantu Anda mengurangi biaya pengeditan dengan mengotomatiskan sebagian besar tugas pasca produksi.
Kreator kini dapat membuat video di luar kreativitas mereka yang terbatas dengan Difusi Stabil. Misalnya, dapat digunakan untuk menghasilkan video dengan efek khusus yang realistis atau untuk menganimasikan gambar diam.
Seperti yang telah saya bahas di atas, Difusi Stabil adalah alat sumber terbuka, yang tersedia secara gratis untuk siapa saja. Hal ini menjadikannya aset kreatif yang berharga bagi siapa saja yang ingin membuat video, terlepas dari keahlian atau anggaran mereka.

Seperti namanya, model AI didasarkan pada praktik difusi yang melatih kecerdasan buatan untuk menghasilkan media yang realistis. Hal ini didasarkan pada tiga prinsip utama:
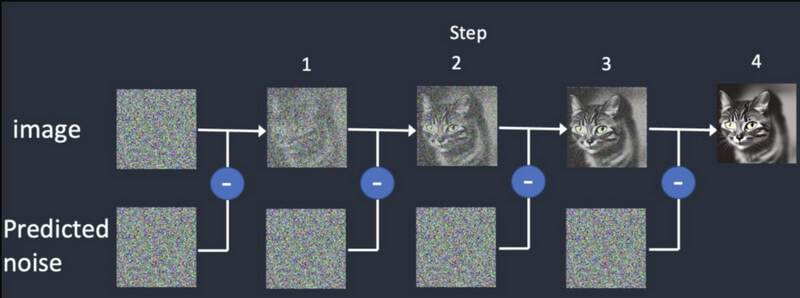
Difusi: Dalam difusi, pertama-tama kita mulai dengan gambar acak dan kemudian terus menambahkan lebih banyak detail secara bertahap. Ini akan terus memberikan keluaran yang berbeda hingga cocok dengan masukan awal. Ini akan melatih Pembuatan Video Difusi Stabil untuk menghasilkan bingkai sintetis, berdasarkan bingkai awal.
Pelatihan: Sama seperti satu gambar, model difusi dilatih pada kumpulan data yang sangat besar. Dengan cara ini, model AI dapat dengan mudah membedakan dan menghasilkan semua jenis objek realistis.
Pembuatan video: Setelah model dilatih, pengguna dapat memuat gambar ke model AI. Model ini akan memperhalus noise untuk setiap frame dan menghasilkan keluaran yang realistis, berdasarkan masukan yang diberikan untuk warna, rotasi, pergeseran visual, dll.
Difusi Video Stabil baru dirilis dan memiliki beberapa keterbatasan, antara lain sebagai berikut:
Kabar baiknya adalah model AI saat ini Difusi Video Stabil tersedia secara gratis. Menurut Stability AI, mereka telah mengembangkan model tersebut untuk tujuan penelitian sampai sekarang. Anda dapat mengakses kode model di halaman GitHub di sini: https://github.com/Stability-AI/generative-models
Selain itu, dokumentasinya tentang Hugging Face juga dapat Anda akses di sini: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI sendiri telah melakukan penelitian ekstensif dan membandingkan model pembuatan videonya dengan alat lain. Menurut penelitian, Difusi Video Stabil dibandingkan dengan model seperti Runway dan Pika Labs.

Di sini, Anda dapat melihat performa model ini dalam menghasilkan 14 dan 25 frame pada kecepatan khusus 3-30 fps. Difusi Stabil juga lebih bertenaga dibandingkan dengan Difusi Video Google dan DALL.E dalam hal menghasilkan video realistis.
| Model | Kekuatan | Kelemahan |
| Difusi Video Stabil | Hasil yang realistis dan koheren, bagus untuk video pendek dari gambar diam | Durasi terbatas, variasi kualitas, kontrol materi iklan terbatas |
| Difusi Video Google | Dapat menghasilkan video yang lebih panjang, bagus untuk pembuatan teks-ke-video | Dapat menghasilkan kesalahan, memerlukan penyesuaian (tidak terlalu stabil) |
| DALL-E 2 | Sangat kreatif dan eksperimental | Bisa jadi kurang stabil |
| landasan pacu ML | Mudah digunakan dan bagus untuk pemula | Kemampuannya terbatas dan tidak sekuat model lainnya |
| Lab Pika | Sumber terbuka | Basis pengguna terbatas, masih dalam pengembangan |
Tidak – sampai sekarang, hasil dari Pembuatan video Difusi Stabil dibatasi hingga 4 detik saja. Namun, dalam versi AI yang akan datang, kami mungkin berharap AI ini juga menghasilkan video berdurasi panjang.
Berikut adalah beberapa persyaratan untuk berjalan Difusi Video Stabil:
| Persyaratan | Minimum | Direkomendasikan |
| GPU | VRAM 6GB | VRAM 10 GB (atau lebih tinggi) |
| CPU | 4 inti | 8 inti (atau lebih tinggi) |
| RAM | 16GB | 32GB (atau lebih tinggi) |
| Penyimpanan | 10GB | 20GB (atau lebih tinggi) |
Selain itu, Anda harus menginstal Python 3.10 (atau lebih tinggi) di sistem Anda terlebih dahulu.
Saat ini, Stability AI baru dirilis Difusi Video Stabil untuk tujuan penelitian sehingga model dapat berkembang. Namun, di masa depan, model AI mungkin akan berkembang dalam beberapa fitur berikut:
Saya yakin setelah membaca postingan ini, Anda dapat dengan mudah memahami cara kerjanya Pembuatan Video Difusi Stabil bekerja. Saya juga telah memberikan beberapa langkah cepat yang dapat Anda ambil untuk memulai Difusi Video Stabil Anda sendiri. Meskipun demikian, Anda harus ingat bahwa model AI relatif baru, masih belajar, dan mungkin tidak memenuhi kebutuhan Anda. Silakan – cobalah model video generatif Stability AI dan teruslah bereksperimen dengannya untuk mengeluarkan kreativitas Anda!