Assinatura do boletim informativo
Digite seu endereço de e-mail abaixo e assine nosso boletim informativo
Digite seu endereço de e-mail abaixo e assine nosso boletim informativo
Ferramentas gratuitas


Modelos de moda com IA
Exiba roupas em modelos de IA

Fotos de limpeza
Remover objetos indesejados

Alterador de plano de fundo
Planos de fundo instantâneos gerados por IA

Recolorir roupas
Substitua a cor em um clique

Direitos autorais da imagem
Obtenha fotos livres de royalties do reimagine

Removedor de plano de fundo
Fundo transparente ou de qualquer cor

Aprimorador de fotos
Melhorar a qualidade da imagem
Baixar o aplicativo

Você já deve saber como criar imagens geradas por IA com a ajuda do Stable Diffusion. Agora, você também pode dar uma nova vida a essas imagens com gráficos em movimento gerados por IA. Bem-vindo ao Estábulo Vídeo Difusão o que pode ajudá-lo a transformar suas imagens estáticas em vídeos dinâmicos. Neste post, contarei a você tudo o que é importante sobre o Geração de vídeo de difusão estável e como você pode usá-lo como um profissional.

Como você sabe, Stable Diffusion é um modelo de IA de código aberto criado pela Stability AI. Com Stable Diffusion, você pode gerar imagens simplesmente inserindo instruções de texto. Agora, com a versão em vídeo do Stable Diffusion, você pode converter suas imagens em vídeos curtos gratuitamente.
O modelo de IA toma a imagem como um quadro de origem e cria quadros subsequentes usando uma técnica única, conhecida como difusão. Idealmente, a técnica adiciona vários detalhes (seja do fundo ou do objeto) a uma imagem de origem, tornando-a um vídeo. A Stability AI treinou o modelo com base em um grande conjunto de vídeos e fotos realistas, que podem ser executados virtualmente ou em um sistema local.

Geral, Difusão de vídeo estável é uma ferramenta poderosa que pode ajudá-lo a criar todos os tipos de vídeos – desde conteúdo criativo até conteúdo educacional. Embora tenha sido lançado recentemente, o modelo ainda está em desenvolvimento e espera-se que evolua no futuro.
Atualmente, você pode usar o recurso de vídeo do Stable Diffusion de duas maneiras – você pode instalá-lo em seu sistema ou aproveitar qualquer aplicativo baseado na web.
Desde Vídeo de difusão estável AI para vídeo grátis solução é uma oferta de código aberto, várias ferramentas de terceiros a integraram em suas plataformas. Por exemplo, você pode visitar o site: https://stable-video-diffusion.com/ e carregue sua foto. Assim que a foto for carregada, a ferramenta irá analisá-la automaticamente e convertê-la em um vídeo.
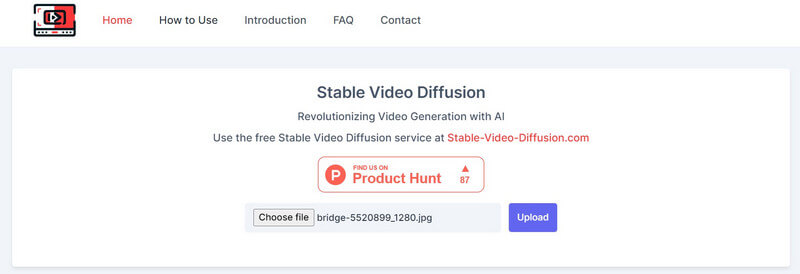
É isso! Em poucos segundos, a ferramenta online irá gerar um pequeno vídeo baseado na foto enviada. Você pode simplesmente visualizar o vídeo aqui e baixá-lo em seu sistema.
Se quiser obter resultados mais personalizados (e não filtrados), você também pode considerar a instalação do módulo AI em Vídeo estável Difusão em seu sistema. Porém, você deve saber que o processo é um pouco técnico e consumirá recursos computacionais substanciais.
Pré-requisitos:
Depois de atender aos requisitos acima, você pode iniciar o console do Python em seu sistema. Agora, você pode executar os seguintes comandos um por um, que criarão, ativarão e instalarão as dependências necessárias em seu sistema para executar o Stable Diffusion.
python3 -m venv venv
origem venv/bin/ativar
pip instalar -r requisitos.txt
Assim que o ambiente estiver instalado e funcionando em seu sistema, você poderá preparar uma imagem de entrada. Se você não tiver uma imagem, poderá usar o Stable Diffusion AI padrão para criar uma inserindo texto.
Para gerar o vídeo, você pode simplesmente navegar no difusão de vídeo estável direção em seu sistema. Basta digitar o seguinte comando para gerar o vídeo, usando uma imagem de entrada:
python3 scripts/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt “texto de prompt” –fps 6 –num_frames 100 –augmentation_level 0,5
Observe que no comando acima, você precisa fazer o seguinte:
Depois de inserir o prompt, você pode esperar um pouco enquanto o Geração de vídeo de difusão estável conclui seu processamento. Se o processo for mais complexo, poderá demorar um pouco para que a Difusão Estável gere seus resultados.
Assim que a geração do vídeo for concluída, ele será salvo no saída diretório com o carimbo de data/hora como nome.
Desta forma, você pode usar o Vídeo de difusão estável AI para vídeo grátis (ou foto para vídeo grátis) ferramenta para gerar vídeos. Você pode experimentar ainda mais vários prompts e configurações de entrada para ajustar os resultados.
Em poucas palavras, a Difusão Estável é uma Modelo de IA criado pela Stability AI para gerar conteúdo de mídia de alta qualidade (fotos e vídeos). É uma versão mais estável dos modelos anteriores, que gera imagens realistas e sem erros.
Por outro lado, Unstable Diffusion é a sua contraparte mais criativa e irrestrita. Ao contrário do Stable Diffusion, que foi treinado em um conjunto de dados de imagens filtradas, o Unstable Diffusion tem imagens não filtradas como seu conjunto de dados. É por isso que a Difusão Instável pode muitas vezes levar a erros nos seus resultados e produz um trabalho mais abstrato do que realista.

Desde Difusão de vídeo estável ainda está em evolução, é difícil prever o seu impacto real, mas pode ter a seguinte influência:
Como você sabe, o Stable Diffusion pode gerar vídeos em segundos, o que pode ajudar os criadores de conteúdo a economizar tempo. Você pode criar animações, adicionar efeitos especiais ou transferir estilos de vídeos instantaneamente, em vez de gastar horas editando.
Os esforços manuais que colocamos na edição de vídeo podem ser caros e demorados. Por outro lado, Difusão de vídeo estável pode ajudá-lo a reduzir esses custos de edição, automatizando a maioria das tarefas de pós-produção.
Os criadores agora podem criar vídeos além de sua criatividade restrita com o Stable Diffusion. Por exemplo, pode ser usado para gerar vídeos com efeitos especiais realistas ou para animar imagens estáticas.
Como discuti acima, Stable Diffusion é uma ferramenta de código aberto, disponível gratuitamente para qualquer pessoa. Isso o torna um recurso criativo valioso para quem deseja criar vídeos, independentemente de suas habilidades ou orçamento.

Como o nome sugere, o modelo de IA é baseado em uma prática de difusão que treina a inteligência artificial para gerar mídia realista. Baseia-se em três princípios principais:
Difusão: Na difusão, primeiro começamos com uma imagem aleatória e depois adicionamos mais detalhes a ela gradualmente. Ele continuará fornecendo saídas diferentes até corresponder à entrada inicial. Isto irá treinar o Geração de vídeo de difusão estável criar armações sintéticas, baseadas na inicial.
Treinamento: Assim como uma imagem, o modelo de difusão é treinado em um grande conjunto de dados. Desta forma, o modelo de IA pode distinguir e gerar facilmente todos os tipos de objetos realistas.
Geração de vídeo: depois que o modelo for treinado, os usuários poderão carregar uma imagem no modelo de IA. O modelo irá refinar o ruído de cada quadro e apresentar resultados realistas, com base nas entradas fornecidas para cores, rotações, mudanças visuais, etc.
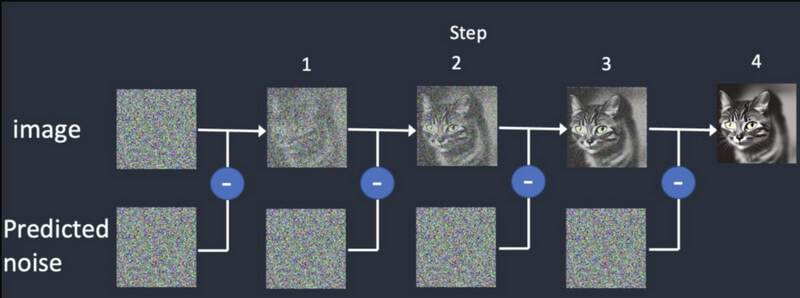
Difusão de vídeo estável foi lançado recentemente e tem várias limitações, incluindo as seguintes:
A boa notícia é que o atual modelo de IA do Difusão de vídeo estável está disponível gratuitamente. De acordo com a Stability AI, ela desenvolveu o modelo para fins de pesquisa a partir de agora. Você pode acessar o código do modelo em sua página GitHub aqui: https://github.com/Stability-AI/generative-models
Além disso, você pode acessar a documentação do Hugging Face aqui: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
A própria Stability AI realizou extensas pesquisas e comparou seu modelo de geração de vídeo com outras ferramentas. Segundo a pesquisa, o Stable Video Diffusion é comparado com modelos como Runway e Pika Labs.

Aqui você pode ver o desempenho desses modelos na geração de 14 e 25 quadros a uma taxa personalizada de 3 a 30 fps. O Stable Diffusion também é mais poderoso em comparação com o Google Video Diffusion e o DALL.E quando se trata de gerar vídeos realistas.
| Modelo | Força | Fraqueza |
| Difusão de vídeo estável | Resultados realistas e coerentes, bons para vídeos curtos de imagens estáticas | Duração limitada, variações de qualidade, controle criativo limitado |
| Difusão de vídeos do Google | Pode gerar vídeos mais longos, bons para geração de texto para vídeo | Pode produzir erros, requer ajuste fino (não tão estável) |
| DALL-E 2 | Altamente criativo e experimental | Pode ser menos estável |
| Pista ML | Fácil de usar e bom para iniciantes | Capacidades limitadas e não tão poderosas quanto outros modelos |
| Laboratórios Pika | Código aberto | Base de usuários limitada, ainda em desenvolvimento |
Não – a partir de agora, os resultados do Geração de vídeo de difusão estável são limitados a apenas 4 segundos. No entanto, nas próximas versões desta IA, podemos esperar que ela também gere vídeos de longa duração.
Aqui estão alguns dos requisitos para executar Difusão de vídeo estável:
| Requerimento | Mínimo | Recomendado |
| GPU | 6 GB de RAM | 10 GB de VRAM (ou superior) |
| CPU | 4 núcleos | 8 núcleos (ou superior) |
| BATER | 16 GB | 32 GB (ou superior) |
| Armazenar | 10 GB | 20 GB (ou superior) |
Além disso, você deve instalar previamente o Python 3.10 (ou superior) em seu sistema.
Atualmente, Stability AI lançou apenas Difusão de vídeo estável para fins de pesquisa para que o modelo possa evoluir. No entanto, no futuro, podemos esperar que o modelo de IA evolua nas seguintes características:
Tenho certeza que depois de ler este post, você poderá entender facilmente como o Geração de vídeo de difusão estável funciona. Também sugeri algumas etapas rápidas que você pode seguir para começar Difusão de vídeo estável por si só. Porém, você deve se lembrar que o Modelo de IA é relativamente novo, ainda está aprendendo e pode não atender exatamente aos seus requisitos. Vá em frente – experimente o modelo de vídeo generativo Stability AI e continue experimentando-o para liberar sua criatividade!