Iscrizione alla newsletter
Inserite il vostro indirizzo e-mail e iscrivetevi alla nostra newsletter.
Inserite il vostro indirizzo e-mail e iscrivetevi alla nostra newsletter.
Strumenti gratuiti


Modelli di moda AI
Abiti in vetrina su modelli AI

Immagini di pulizia
Rimuovere gli oggetti indesiderati

Cambiamento di sfondo
Sfondi istantanei generati dall'intelligenza artificiale

Ricolorazione dell'abbigliamento
Sostituire il colore in 1 clic

Immagine Ricopyright
Ottenere foto royalty-free di reimagine

Rimozione dello sfondo
Sfondo trasparente o di qualsiasi colore

Miglioratore di foto
Migliorare la qualità dell'immagine
Scarica l'APP

Potresti già sapere come creare immagini generate dall'intelligenza artificiale con l'aiuto di Stable Diffusion. Ora puoi dare a quelle immagini una nuova vita anche con la grafica in movimento generata dall'intelligenza artificiale. Benvenuto a Stabile video Diffusione che può aiutarti a trasformare le tue immagini statiche in video dinamici. In questo post ti farò sapere ogni cosa importante sul Generazione video a diffusione stabile e come puoi usarlo come un professionista.

Come sai, Stable Diffusion è un modello di intelligenza artificiale open source creato da Stability AI. Con Stable Diffusion, puoi generare immagini semplicemente inserendo istruzioni di testo. Ora, con la versione video di Stable Diffusion, puoi convertire gratuitamente le tue immagini in brevi video.
Il modello AI prende l'immagine come fotogramma sorgente e crea fotogrammi successivi utilizzando una tecnica unica, nota come diffusione. La tecnica aggiunge idealmente vari dettagli (sia per lo sfondo che per l'oggetto) a un'immagine sorgente, rendendola un video. Stability AI ha addestrato il modello sulla base di un ampio set di video e foto realistici, che possono essere eseguiti virtualmente o su un sistema locale.

Complessivamente, Diffusione video stabile è un potente strumento che può aiutarti a creare tutti i tipi di video, dai contenuti creativi a quelli educativi. Sebbene sia stato rilasciato di recente, il modello è ancora in fase di sviluppo e si prevede che si evolverà in futuro.
Al momento, puoi utilizzare la funzionalità video di Stable Diffusion in due modi: puoi installarla sul tuo sistema o sfruttare qualsiasi applicazione basata sul web.
Da Video AI a diffusione stabile in video gratuiti La soluzione è un'offerta open source, vari strumenti di terze parti l'hanno integrata sulle loro piattaforme. Ad esempio, puoi visitare il sito web: https://stable-video-diffusion.com/ e carica la tua foto. Una volta caricata la foto, lo strumento la analizzerà automaticamente e la convertirà in un video.
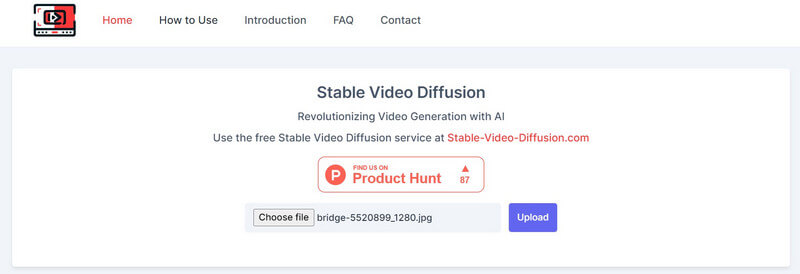
Questo è tutto! In pochi secondi, lo strumento online genererà un breve video basato sulla foto caricata. Puoi semplicemente visualizzare l'anteprima del video qui e scaricarlo sul tuo sistema.
Se desideri ottenere risultati più personalizzati (e non filtrati), puoi anche prendere in considerazione l'installazione del modulo AI da Video stabile Diffusione sul tuo sistema. Tuttavia, dovresti sapere che il processo è un po' tecnico e consumerà notevoli risorse di calcolo.
Prerequisiti:
Una volta soddisfatti i requisiti di cui sopra, puoi avviare la console Python sul tuo sistema. Ora puoi eseguire i seguenti comandi uno per uno, che creeranno, attiveranno e installeranno le dipendenze richieste sul tuo sistema per eseguire Stable Diffusion.
python3 -m venv venv
sorgente venv/bin/activate
pip install -r requisiti.txt
Una volta che l'ambiente è attivo e funzionante sul tuo sistema, puoi preparare un'immagine di input. Se non disponi di un'immagine, puoi utilizzare l'AI Stable Diffusion standard per crearne una inserendo il testo.
Per generare il video, puoi semplicemente navigare nel file diffusione video stabile direzione sul sistema. Basta inserire il seguente comando per generare il video, utilizzando un'immagine di input:
python3 scripts/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt “testo prompt” –fps 6 –num_frames 100 –augmentation_level 0.5
Tieni presente che nel comando precedente, devi fare le seguenti cose:
Dopo aver inserito il prompt, puoi attendere qualche istante perché il file Generazione video a diffusione stabile completa la sua elaborazione. Se il processo è più complesso, potrebbe essere necessario del tempo prima che Stable Diffusion generi i suoi risultati.
Una volta completata la generazione del video, verrà salvato nel file produzione directory con il timestamp come nome.
In questo modo è possibile utilizzare il Video AI a diffusione stabile in video gratuiti (o strumento gratuito per foto e video) per generare video. Puoi sperimentare ulteriormente vari prompt e impostazioni di input per modificare i risultati.
In poche parole, la diffusione stabile è un Modello di intelligenza artificiale creato da Stability AI per generare contenuti multimediali di alta qualità (foto e video). Si tratta di una versione più stabile dei modelli precedenti, che genera immagini realistiche senza errori.
D'altra parte, Unstable Diffusion è la sua controparte più creativa e senza restrizioni. A differenza di Stable Diffusion, che è stato addestrato su un set di dati di immagini filtrate, Unstable Diffusion ha immagini non filtrate come set di dati. Ecco perché Unstable Diffusion può spesso portare a errori nei risultati e produce un lavoro più astratto che realistico.

Da Diffusione video stabile è ancora in evoluzione, è difficile prevederne l’impatto effettivo, ma può avere la seguente influenza:
Come sai, Stable Diffusion può generare video in pochi secondi, il che può aiutare i creatori di contenuti a risparmiare tempo. Puoi creare animazioni, aggiungere effetti speciali o trasferire stili di video istantaneamente invece di dedicare ore alla modifica.
Gli sforzi manuali che dedichiamo all'editing video possono essere costosi e richiedere molto tempo. D'altra parte, Diffusione video stabile può aiutarti a ridurre questi costi di editing automatizzando la maggior parte delle attività di post-produzione.
I creatori possono ora realizzare video che vanno oltre la loro creatività limitata con Stable Diffusion. Può essere utilizzato, ad esempio, per generare video con effetti speciali realistici o per animare immagini fisse.
Come ho discusso in precedenza, Stable Diffusion è uno strumento open source, disponibile gratuitamente per chiunque. Ciò lo rende una preziosa risorsa creativa per chiunque desideri creare video, indipendentemente dalle proprie competenze o dal proprio budget.

Come suggerisce il nome, il modello di intelligenza artificiale si basa su una pratica di diffusione che addestra l’intelligenza artificiale a generare media realistici. Si basa su tre principi fondamentali:
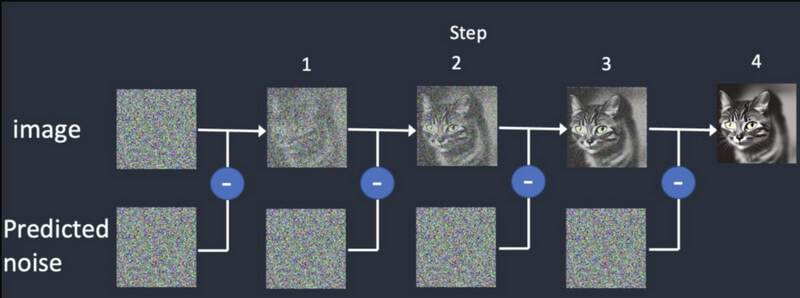
Diffusione: Nella diffusione, iniziamo prima con un'immagine casuale e poi continuiamo ad aggiungere gradualmente ulteriori dettagli. Continuerà a fornire output diversi finché non corrisponderà all'input iniziale. Questo addestrerà il Generazione video a diffusione stabile per elaborare frame sintetici, basati su quello iniziale.
Formazione: Proprio come un'immagine, il modello di diffusione viene addestrato su un enorme set di dati. In questo modo, il modello AI può facilmente distinguere e generare tutti i tipi di oggetti realistici.
Generazione video: una volta addestrato il modello, gli utenti possono caricare un'immagine nel modello AI. Il modello perfezionerà il rumore per ciascun fotogramma e fornirà risultati realistici, in base agli input forniti per colori, rotazioni, spostamenti visivi, ecc.
Diffusione video stabile è stato recentemente rilasciato e presenta diverse limitazioni, tra cui le seguenti:
La buona notizia è che l'attuale modello di intelligenza artificiale di Diffusione video stabile è disponibile gratuitamente. Secondo Stability AI, sin da ora ha sviluppato il modello per scopi di ricerca. Puoi accedere al codice del modello sulla sua pagina GitHub qui: https://github.com/Stability-AI/generative-models
Oltre a ciò, puoi accedere alla documentazione su Hugging Face qui: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI ha effettuato ricerche approfondite e ha confrontato il suo modello di generazione video con altri strumenti. Secondo la ricerca, Stable Video Diffusion viene confrontato con modelli come Runway e Pika Labs.

Qui puoi vedere come si comportano questi modelli nel generare 14 e 25 fotogrammi a una velocità personalizzata di 3-30 fps. Stable Diffusion è anche più potente rispetto a Google Video Diffusion e DALL.E quando si tratta di generare video realistici.
| Modello | Forza | Debolezza |
| Diffusione video stabile | Risultati realistici e coerenti, ideali per brevi video da immagini fisse | Durata limitata, variazioni di qualità, controllo creativo limitato |
| Diffusione video di Google | Può generare video più lunghi, ideali per la generazione di testo in video | Può produrre errori, richiede una messa a punto (non così stabile) |
| DALL-E 2 | Altamente creativo e sperimentale | Può essere meno stabile |
| Pista ML | Facile da usare e adatto ai principianti | Capacità limitate e non potenti come altri modelli |
| Pika Labs | Open source | Base utenti limitata, ancora in fase di sviluppo |
No, per ora i risultati del Generazione video a diffusione stabile sono limitati solo a un massimo di 4 secondi. Tuttavia, nelle prossime versioni di questa IA, potremmo aspettarci che generi anche video di lunga durata.
Ecco alcuni requisiti per correre Diffusione video stabile:
| Requisiti | Minimo | Consigliato |
| GPU | 6 GB di RAM | 10 GB VRAM (o superiore) |
| processore | 4 nuclei | 8 core (o superiore) |
| RAM | 16 GB | 32 GB (o superiore) |
| Magazzinaggio | 10 GB | 20 GB (o superiore) |
Oltre a ciò, dovresti prima installare Python 3.10 (o versione successiva) sul tuo sistema.
Attualmente, Stability AI è stato rilasciato solo Diffusione video stabile a fini di ricerca in modo che il modello possa evolversi. Tuttavia, in futuro, potremmo aspettarci che il modello di intelligenza artificiale si evolva nelle seguenti funzionalità:
Sono sicuro che dopo aver letto questo post, potrai facilmente capire come funziona il Generazione video a diffusione stabile lavori. Ho anche ideato alcuni passaggi rapidi che puoi eseguire per iniziare Diffusione video stabile per conto proprio. Tuttavia, dovresti ricordare che il Modello di intelligenza artificiale è relativamente nuovo, sta ancora imparando e potrebbe non soddisfare esattamente i tuoi requisiti. Vai avanti: prova il modello video generativo Stability AI e continua a sperimentarlo per liberare la tua creatività!